Pre-Training a 1B LLM from Scratch on SageMaker HyperPod with Slurm
- 11 minsMost teams fine-tune. This post is about pre-training. Taking a Llama 3.2 1B architecture with random weights and training it from zero on the C4 English web text dataset using 16 NVIDIA A10G GPUs across 4 nodes on Amazon SageMaker HyperPod, orchestrated by Slurm, with PyTorch FSDP handling the distributed training.
Karpathy's microgpt showed how to train a GPT in 200 lines of pure Python on a CPU. This post takes that same algorithm and runs it at scale. 1 billion parameters, billions of tokens, 16 GPUs, distributed across 4 nodes. The core loop doesn't change: predict next token, compute loss, backpropagate, update weights. Everything else you'll see here (VPC, FSx, Slurm, NCCL, EFA, FSDP) is the infrastructure to make that loop run fast enough that it finishes in days instead of centuries.
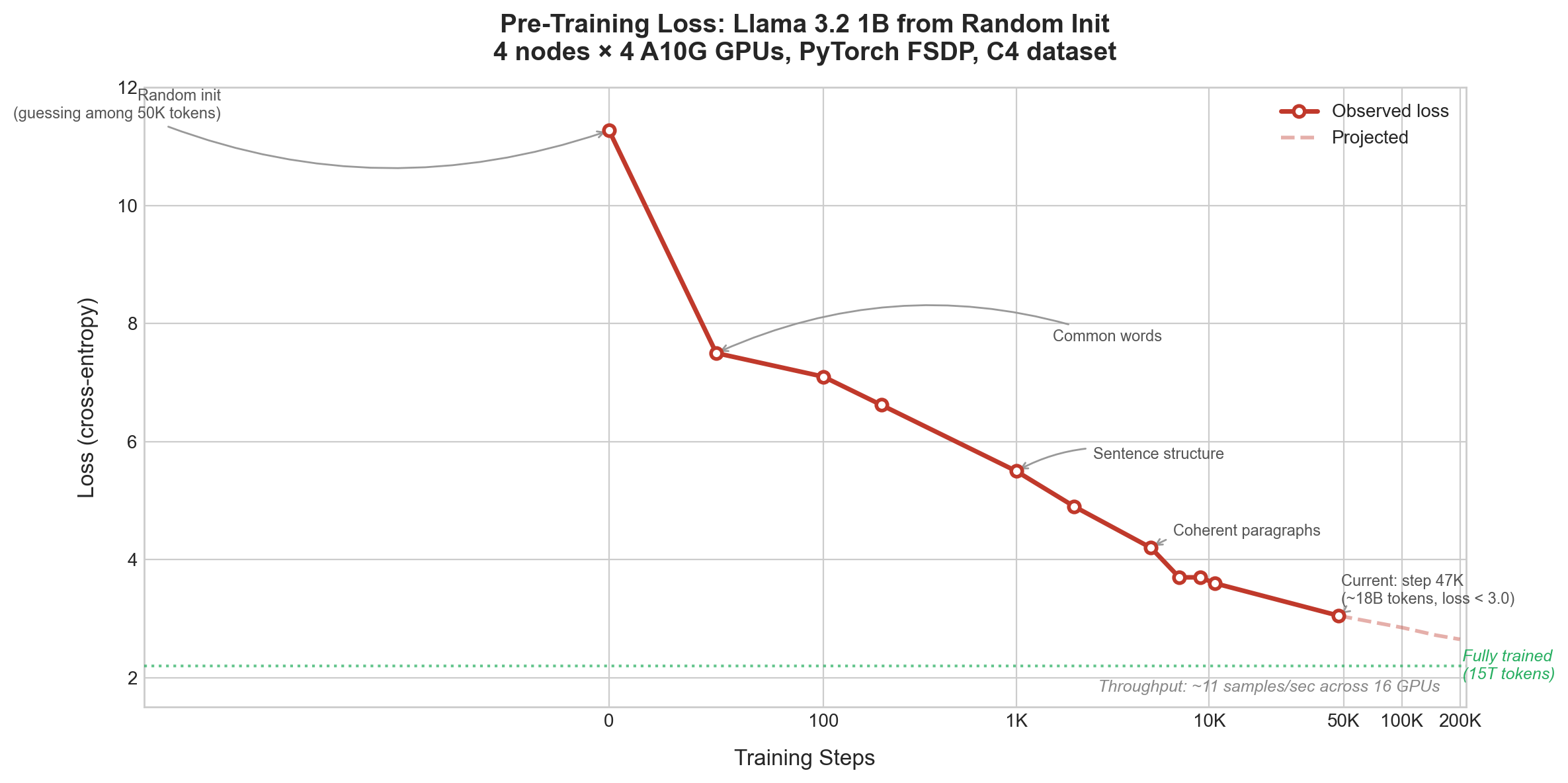
From random noise to fluent English in 47,000 steps. This post walks through every layer of the stack that made it happen.
The setup
The model is Llama 3.2 1B. 1.15 billion parameters, 16 transformer layers, 2048 hidden dimension, 32 attention heads with Grouped Query Attention (2 KV heads), RoPE positional encoding, SwiGLU activations, RMSNorm. We use the architecture only. No pre-trained weights. Everything starts random.
The dataset is allenai/c4, the English split of Common Crawl. We stream it, no need to download the whole thing upfront.
The hardware is 4x ml.g5.12xlarge instances on SageMaker HyperPod, each with 4 NVIDIA A10G GPUs (24 GB each), 48 vCPUs, and 192 GB RAM. That's 16 GPUs total. Plus one ml.c5.xlarge as the Slurm controller. It doesn't train, it just schedules jobs. All nodes share a 1.2 TB FSx for Lustre filesystem mounted at /fsx. Code, virtual environments, checkpoints, cached data, everything lives there.
The distributed training strategy is PyTorch FSDP (Fully Sharded Data Parallel). Slurm orchestrates the cluster. NCCL handles GPU-to-GPU communication over EFA (Elastic Fabric Adapter).
The awsome-distributed-training repository from AWS Labs provides reference architectures, lifecycle scripts, and training test cases for HyperPod. I used it as a starting point. The FSDP training scripts and lifecycle scripts come from there. On top of that, I wrote:
- 10 composable Terraform modules to provision the full infrastructure stack in one
terraform apply - A custom sbatch script tuned for g5.12xlarge (4 GPUs per node, activation offloading, 8K context)
- Checkpoint consolidation scripts to convert FSDP distributed checkpoints into standard HuggingFace format
- Evaluation scripts to track model quality across training stages
Infrastructure
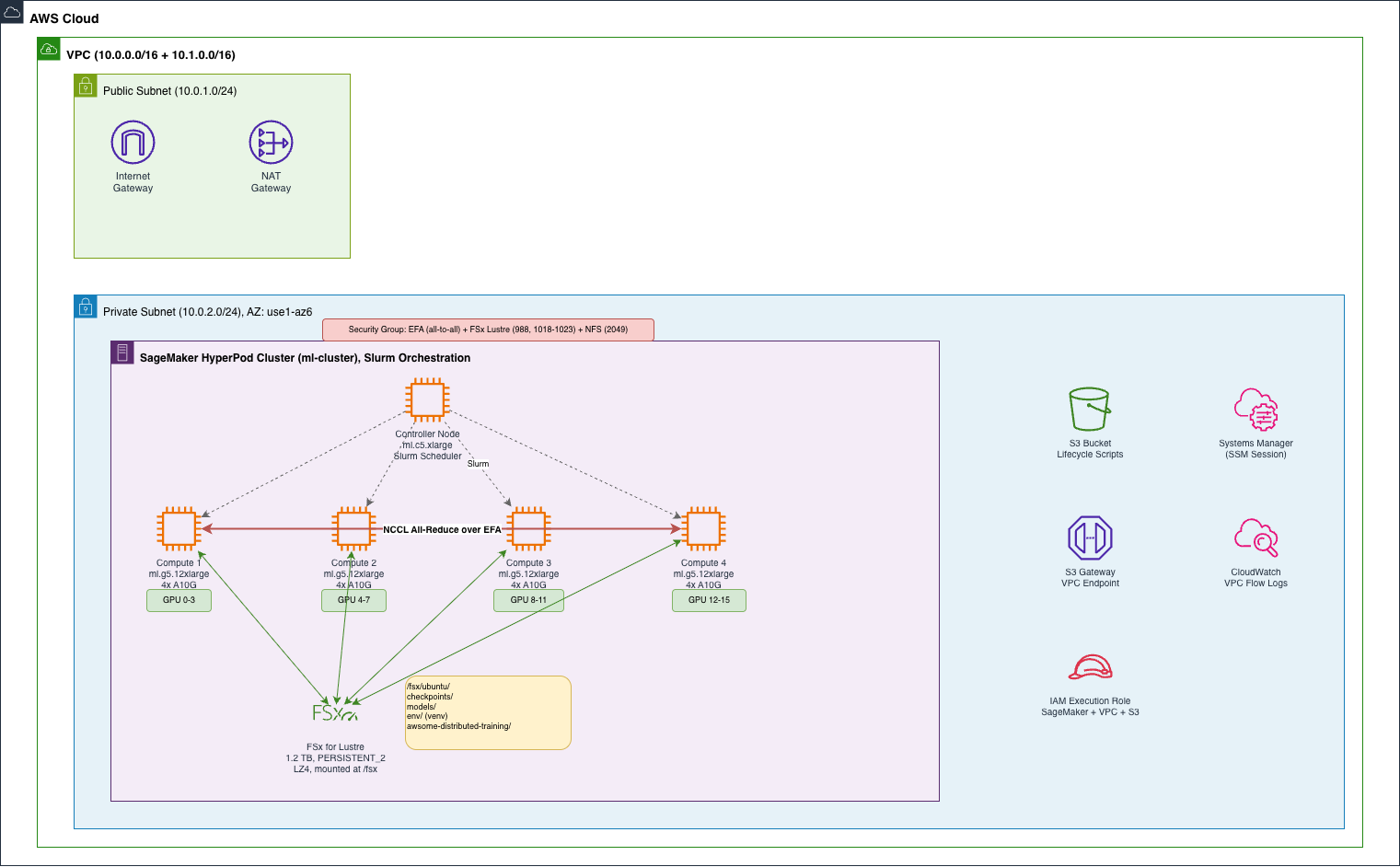
The infrastructure is three layers. Network: a VPC with public and private subnets, a NAT Gateway, and an S3 VPC endpoint so nodes can reach S3 without going through the NAT. Storage: FSx for Lustre as the shared filesystem, and an S3 bucket for lifecycle scripts. Compute: the HyperPod cluster itself.
I wrote 10 Terraform modules to provision all of this: vpc, private_subnet, security_group, s3_bucket, s3_endpoint, fsx_lustre, fsx_openzfs, lifecycle_script, sagemaker_iam_role, and hyperpod_cluster. The awsome-distributed-training repo has Terraform modules for HyperPod as well. I built my own set to have full control over composability. Every module is optional. If you already have a VPC, set create_vpc_module = false and pass your existing VPC ID. Same pattern for every resource:
module "vpc" {
count = var.create_vpc_module ? 1 : 0
source = "./modules/vpc"
}
locals {
vpc_id = var.create_vpc_module ? module.vpc[0].vpc_id : var.existing_vpc_id
}The security group deserves a mention. It needs self-referencing rules (all ports, all protocols) so every node can talk to every other node. That's how EFA works for GPU-to-GPU communication. It also needs FSx Lustre LNET rules on port 988 and ports 1018-1023. Without these, NCCL can't do all-reduce across nodes and FSx won't mount. Getting these wrong is a silent failure. Things just hang.
The lifecycle_script module is the glue between Terraform and HyperPod. It uploads the Slurm bootstrap scripts to S3 and generates provisioning_parameters.json dynamically from the Terraform variables. This file tells HyperPod which node is the controller, which are compute, and where to find FSx.
Deployment is three commands:
terraform init
terraform plan
terraform apply # ~15 minutes for the full stackHere's the terraform.tfvars I used:
resource_name_prefix = "hyperpod"
aws_region = "us-east-1"
availability_zone_id = "use1-az6"
hyperpod_cluster_name = "ml-cluster"
instance_groups = {
controller-machine = {
instance_type = "ml.c5.xlarge"
instance_count = 1
ebs_volume_size = 100
threads_per_core = 2
lifecycle_script = "on_create.sh"
}
compute-nodes = {
instance_type = "ml.g5.12xlarge"
instance_count = 4
ebs_volume_size = 500
threads_per_core = 2
lifecycle_script = "on_create.sh"
}
}
fsx_lustre_storage_capacity = 1200
fsx_lustre_throughput_per_unit = 125When you're done, terraform destroy tears everything down. No ongoing costs.
When HyperPod provisions a node, it downloads lifecycle scripts from S3 and runs on_create.sh. This mounts FSx Lustre, starts Slurm daemons, installs Docker/Enroot/Pyxis, and sets up passwordless SSH between nodes. The config.py file has feature flags for optional components like observability, LDAP integration, and OpenZFS. Once all nodes finish bootstrapping, sinfo shows 4 idle compute nodes with 4 GPUs each. Ready to submit jobs.
Training
FSDP (Fully Sharded Data Parallel) is how we fit a 1B parameter model across 16 GPUs. It splits model weights, gradients, and optimizer states so each GPU only holds 1/16 of the total. During each training step, FSDP temporarily gathers the full layer weights (all-gather), runs the forward pass on the local batch, discards the gathered weights, runs the backward pass, synchronizes gradients across all GPUs (reduce-scatter), and each GPU updates its own shard with Adam. The communication happens over NCCL using EFA.
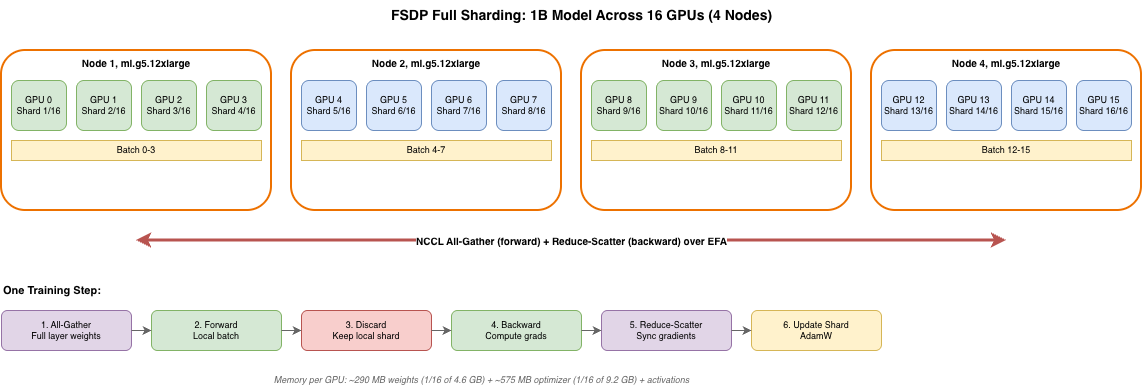
A 1B parameter model in fp32 needs about 4.6 GB for weights alone, plus 9.2 GB for Adam optimizer states, plus gradients and activations. That's more than a single A10G (24 GB) can handle comfortably. FSDP distributes this across 16 GPUs so each one only holds a fraction.
The Slurm batch script ties it all together:
#!/bin/bash
#SBATCH --nodes=4
#SBATCH --ntasks-per-node=1
#SBATCH --exclusive
GPUS_PER_NODE=4
srun torchrun \
--nproc_per_node=$GPUS_PER_NODE \
--nnodes=$SLURM_JOB_NUM_NODES \
--rdzv_id=$SLURM_JOB_ID \
--rdzv_backend=c10d \
--rdzv_endpoint=$(hostname) \
train.py \
--max_context_width=8192 \
--num_key_value_heads=2 \
--hidden_width=2048 \
--num_layers=16 \
--num_heads=32 \
--model_type=llama_v3 \
--dataset=allenai/c4 \
--train_batch_size=3 \
--sharding_strategy=full \
--offload_activations=1 \
--max_steps=200000 \
--checkpoint_freq=5000sbatch submits the job. Slurm allocates 4 nodes. srun launches torchrun on all of them. torchrun spawns 4 processes per node, one per GPU, 16 total. FSDP coordinates them via NCCL over EFA. HyperPod's --auto-resume flag means if a node dies, it gets replaced and training picks up from the last checkpoint on FSx.
A note on the hyperparameters: the effective batch size is 3 × 16 GPUs × 8192 tokens = ~393K tokens/step. That's on the small side for a 1B model (most published runs use 1-4M tokens/step), but it keeps memory comfortable on A10G with activation offloading. Peak learning rate is 1e-4 with cosine decay to 1e-5 over 200K steps, with a linear warmup over the first few hundred steps. Validation runs every 2,500 steps. On streamed C4 with no epoch boundaries, validation loss tracks training loss closely, no overfitting.
Results
Training is ongoing on 4 nodes (16 GPUs). Results below reflect step ~47,000 after 2 days and 8 hours of training.
The loss starts at 11.27. That's roughly -log(1/50432), the model is randomly guessing among 50K tokens. Over the course of training, it drops:
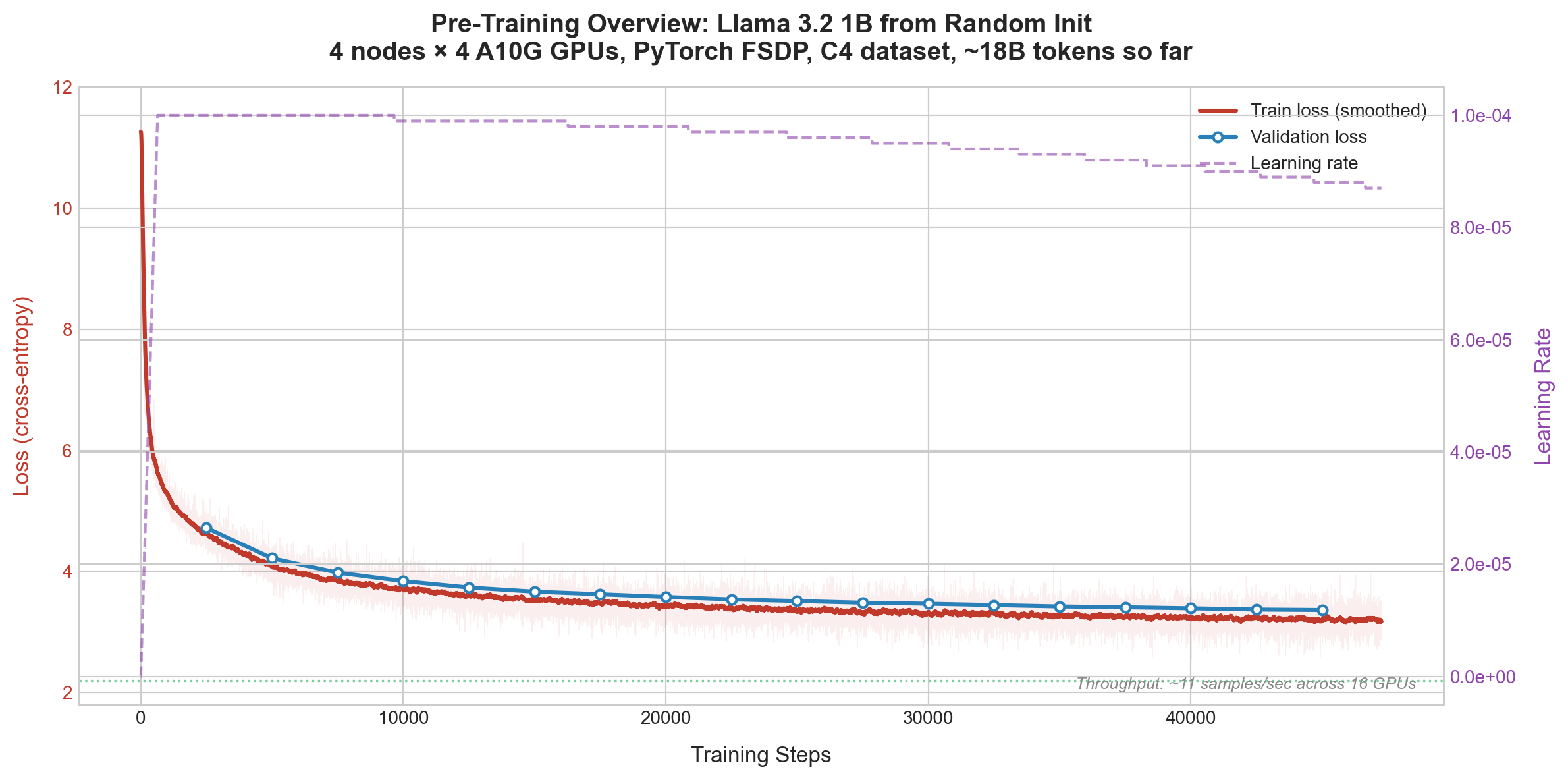
The chart shows raw training loss (faint red), smoothed training loss (solid red), validation loss (blue dots, every 2,500 steps), and the learning rate schedule (dashed purple, right axis). Validation loss tracks training loss closely with a small stable gap (~0.3), confirming no overfitting. This is expected on streamed C4 where the model never sees the same data twice.
At step 0, loss is 11.27. This is what you'd expect from a model that assigns roughly equal probability to all 50,432 tokens in the vocabulary. It has no idea what English is, what words are, or that text has structure.
By step 50, loss drops to around 7.5. The model figured out which tokens are common. It learned that "the", "and", "in", "of" appear far more often than "önig" or "мов". This is the easiest win: just memorize the frequency distribution of the training data.
By step 1,000, loss is at 5.5. The model learned sentence structure. It knows that articles come before nouns, that sentences end with periods, that capital letters start sentences. The text it generates is grammatically plausible but nonsensical.
By step 2,000, loss is 4.9. Vocabulary gets more varied. Contractions appear ("it's", "there's"). Paragraph structure emerges. The model still doesn't understand meaning, but the surface-level language quality is dramatically better.
By step 5,000, loss is 4.2. The model produces coherent multi-sentence text. It can maintain a topic for several sentences before drifting.
By step 10,000, loss is around 3.6. Fluent English with proper grammar and topic maintenance across paragraphs. But still no factual knowledge.
At step 47,000 (where we are now, ~56 hours in), loss has broken below 3.0 for the first time, fluctuating between 2.97 and 3.35. The learning rate has decayed from 0.0001 to 0.000087 on the cosine schedule. We've seen about 18.4 billion tokens. 9 checkpoints saved so far (every 5K steps).
Throughput has been steady at about 11 samples/sec across all 16 GPUs for the entire run. At this rate, the full 200K steps will take about 2.5 more days. By the end we'll have seen ~78 billion tokens. For reference, a fully trained Llama 3.2 1B trains on 15 trillion tokens and reaches loss 2.0–2.5. We're at 0.12% of that data budget, and the loss is still dropping.
Checkpoint consolidation
FSDP saves distributed checkpoints. Each GPU writes its own shard independently. You can't load these directly for inference. You need to consolidate them into a standard HuggingFace format:
model = AutoModelForCausalLM.from_config(config)
state_dict = {"model": model.state_dict()}
dist_cp.load(state_dict=state_dict,
storage_reader=dist_cp.FileSystemReader(checkpoint_path),
no_dist=True)
model.load_state_dict(state_dict["model"])
model.save_pretrained(output_dir)This produces a model you can load with AutoModelForCausalLM.from_pretrained(). The consolidation script in the repo processes all checkpoints it finds automatically.
What I learned
Start small, scale up. I started with 2 nodes, validated the training loop worked end to end, then scaled to 4. Caught issues early before wasting compute on a multi-day run.
Pin your PyTorch version. The distributed training APIs (FSDP2, distributed checkpoint) are evolving fast. Test that checkpoints save and load correctly before committing to a long run. A 5-day training run that crashes at the first checkpoint save is a painful lesson.
FSx for Lustre is the right call for shared training state. Checkpoints, code, and virtual environments on a shared filesystem means any node can be replaced without data loss. HyperPod's automatic node recovery depends on this.
Terraform over ClickOps. Modular Terraform makes it trivial to spin up, tear down, change instance types, or reuse components. The boolean flags let you bring your own VPC or FSx if you already have them.
FAQ
Why pre-train from scratch instead of fine-tuning an existing model? Fine-tuning starts from a model that already knows English, facts, and reasoning. Pre-training from scratch lets you see exactly what the model learns and when. It's also the only option when you need a model trained on proprietary data from the ground up, or when you want full control over the training data mix.
Why Slurm and not Kubernetes? Slurm is the standard job scheduler in HPC and ML training. It's what most distributed training frameworks (torchrun, DeepSpeed, Megatron) expect. SageMaker HyperPod supports both Slurm and EKS orchestration. Slurm is simpler for pure training workloads where you don't need container orchestration overhead.
Why FSx for Lustre instead of EBS or S3? EBS is per-node, you can't share it across a cluster. S3 is object storage, too slow for random access patterns like reading checkpoints or loading Python packages. FSx for Lustre is a POSIX-compliant parallel filesystem that all nodes mount simultaneously. Checkpoint writes from 16 GPUs hit it concurrently without contention. It also survives node replacements, which is critical for HyperPod's auto-recovery.
Why FSDP instead of DDP or DeepSpeed? DDP (Distributed Data Parallel) replicates the full model on every GPU. That works for smaller models but a 1B model's optimizer states alone exceed a single A10G's memory. FSDP shards everything across GPUs. DeepSpeed ZeRO does the same thing, but FSDP is native PyTorch, no extra dependency, tighter integration with the PyTorch ecosystem, and it's where the PyTorch team is investing.
Will the loss keep going down? Yes. We're at step 47,000 out of 200,000, about 23% into the run. The model has seen roughly 18 billion tokens out of the ~78 billion it will see by the end. The loss just broke below 3.0 for the first time. Scaling laws predict it will continue dropping following a power law. We expect it to land around 2.6-2.8 by the end of the run. A fully trained Llama 3.2 1B (15 trillion tokens) sits around 2.0–2.5. We won't match that without 200x more data, but the model will produce increasingly coherent and factual text.
How much does this cost? The g5.12xlarge instances are the main cost. The exact number depends on how long you run. terraform destroy when you're done, no ongoing charges. The FSx filesystem, NAT Gateway, and controller node add minor costs. The point of the Terraform setup is that you can spin up, train, and tear down without leaving anything running.
Can I use this setup for a larger model? Yes. Change the instance type to P4d or P5 (8 GPUs with NVLink per node), increase the node count, and adjust the model parameters. The Terraform modules, lifecycle scripts, and training scripts all work the same way. The main things that change are the instance type in terraform.tfvars, GPUS_PER_NODE in the sbatch script, and the model architecture flags.
Code
Everything builds on top of the awsome-distributed-training repository. The key paths:
- HyperPod lifecycle scripts for Slurm cluster bootstrap
- HyperPod Terraform modules for infrastructure provisioning
- FSDP training scripts for the training loop, model config, and checkpointing
What I added on top: composable Terraform with per-module toggles, a custom sbatch for g5.12xlarge with 4-node FSDP, checkpoint consolidation (FSDP shards to HuggingFace format), and evaluation scripts for tracking model quality over training. The key code snippets are inline in this post. The reference repo above is the starting point for anyone looking to reproduce this.

Tareq Haschemi
just some experiments with data