
Feature Selection für Machine Learning - Predictive Analytics - Teil 2
- 13 minsEinleitung
Im letzten Beitrag habe ich über die univariate Merkmalauswahl geschrieben, bei der jedes Feature unabhängig in Bezug auf die Zielvariable bewertet wird. Ein weiterer Ansatz besteht darin, Machine Learning Modelle für das Feature-Ranking zu verwenden. Einige Machine Learning Modelle liefern bereits eine inhärente interne Rangfolge von Features beim Erstellen solcher Modelle. Solche Modelle können z.B. SVMs, Entscheidungsbäume oder Random-Forests sein.
Dieser Beitrag befasst sich über das Feature-Ranking mit Random-Forest Modellen, welcher ein beliebter Ansatz ist um die Wichtigkeit der Features zu bewerten.
Random-Forest feature importance
Ensemble-Methoden, wie z.B. Random-Forests bieten eine andere Sicht auf die Rolle, die ein Merkmal bei der Zusammenarbeit mit anderen Merkmalen in der Datenmenge spielt. Sie bieten zwei Methoden für die Merkmalsauswahl:
- Mittlere Abnahme der Verunreinigung (eng. mean decrease impurity)
- Mittlere Abnahmegenauigkeit (eng. mean decrease accuracy).
Mean decrease impurity
Wie bekannt sein dürfte, bestehen Random Forests aus einer Anzahl von Entscheidungsbäumen. Jeder Knoten in den Entscheidungsbäumen ist eine Bedingung für ein einzelnes Merkmal, das dafür ausgelegt ist, den Datensatz in zwei aufzuteilen, sodass ähnliche Werte im selben Satz landen. Das Maß, auf dessen Grundlage die Bedingung gewählt wird, wird als Verunreinigung bezeichnet. Für Regressionsbäume ist es eine Varianz. Wird nun ein Baum trainiert, kann berechnet werden, um wie viel jedes Merkmal die gewichtete Verunreinigung in einem Baum verringert. Die Verunreinigungsabnahme für einen kompletten Wald an Bäumen kann nun von jedem Merkmal gemittelt und nach Wichtigkeits Score sortiert werden.
In sklearn sieht das für die Random-Forest implementationen wie folgt aus (gilt für Random Rorest Classifier und Random Rorest Regressor.). Dazu werden wir wieder den Datensatz aus dem ersten Teil nutzen.
Da das trainieren eines Modells ohne Aufbereitung der Daten nicht einfach passieren kann, müssen unsere Daten erstmal aufbereitet werden. Das bedeutet:
- Finden aller kategorischen Daten
- Kontinuierliche und kategorische Daten trennen
- Behandlung der fehlenden Daten für kontinuierliche Daten
- Behandlung der fehlenden Daten für die kategorischen Daten
- Zusammenführen der Daten
from scipy.stats import skew
from sklearn.preprocessing import Normalizer
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestRegressor
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
target = train[train.columns.values[-1]]
def is_outlier(points, thresh = 3.5):
if len(points.shape) == 1:
points = points[:,None]
median = np.median(points, axis=0)
diff = np.sum((points - median)**2, axis=-1)
diff = np.sqrt(diff)
med_abs_deviation = np.median(diff)
modified_z_score = 0.6745 * diff / med_abs_deviation
return modified_z_score > thresh
#Kontinuierliche Daten aufbereiten..
cats = []
for col in train.columns.values:
if train[col].dtype == 'object':
cats.append(col)
df_cont = train.drop(cats, axis=1)
df_cat = train[cats]
for col in df_cont.columns.values:
if np.sum(df_cont[col].isnull()) > 50:
df_cont = df_cont.drop(col, axis = 1)
elif np.sum(df_cont[col].isnull()) > 0:
median = df_cont[col].median()
idx = np.where(df_cont[col].isnull())[0]
df_cont[col].iloc[idx] = median
outliers = np.where(is_outlier(df_cont[col]))
df_cont[col].iloc[outliers] = median
if skew(df_cont[col]) > 0.75:
df_cont[col] = np.log(df_cont[col])
df_cont[col] = df_cont[col].apply(lambda x: 0 if x == -np.inf else x)
df_cont[col] = Normalizer().fit_transform(df_cont[col].reshape(1,-1))[0]
#Kategorische Daten aufbereiten...
for col in df_cat.columns.values:
if np.sum(df_cat[col].isnull()) > 50:
df_cat = df_cat.drop(col, axis = 1)
continue
elif np.sum(df_cat[col].isnull()) > 0:
df_cat[col] = df_cat[col].fillna('MIA')
df_cat[col] = LabelEncoder().fit_transform(df_cat[col])
num_cols = df_cat[col].max()
for i in range(num_cols):
col_name = col + '_' + str(i)
df_cat[col_name] = df_cat[col].apply(lambda x: 1 if x == i else 0)
df_cat = df_cat.drop(col, axis = 1)
#Zusammenführen...
df_new = df_cont.join(df_cat)
df_new = df_new.drop('SalePrice', 1)
x = df_new
y = target
from sklearn.ensemble import RandomForestRegressor
forest = RandomForestRegressor(random_state=0,n_estimators=200,n_jobs=-1)
x = df_new
y = target
forest.fit(x, y)
importances = forest.feature_importances_
df = pd.DataFrame(index=x.columns,data = importances,columns=['Score'])
df = df[df.Score > 0.005600]
df = df.sort_values(by=['Score'],ascending=False)
# Print the feature ranking
print("Feature ranking:")
print(df)
# Plot the feature importances of the forest
plt.plot(figsize=(100, 80))
plt.figure(1, figsize=(90, 85))
plt.title("Bedeutung der Merkmale")
plt.bar(range(df.size), df.Score,
color="g", align="center")
plt.xticks(range(df.size), df.index,rotation=90)
plt.xlim([-1, df.size])
plt.show()
Feature ranking:
Score
OverallQual 0.577820
GrLivArea 0.119003
TotalBsmtSF 0.039044
2ndFlrSF 0.035063
BsmtFinSF1 0.028184
1stFlrSF 0.025042
GarageArea 0.021558
GarageCars 0.014943
YearBuilt 0.014207
LotArea 0.013418
YearRemodAdd 0.009775
TotRmsAbvGrd 0.009451
FullBath 0.006206
BsmtQual_2 0.005692
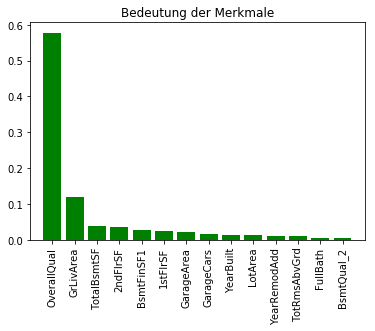
Die Implementierung des Random Forests in scikit-learn ermittelt die Bedeutung von Merkmalen schon während der Anpassung. So lassen sich nach dem Trainieren eines Random-ForestRegressors mit 200 Entscheidungsbäumen, über das Attribut feature-importance auf die Wichtigkeit der Merkmale zugreifen. Nun werden die Ergebnisse abgegriffen und können wie in der obigen Abbildung dargestellt werden. Aus dieser Abbildung lässt sich schließen, dass OverallQual das hervorstechendsten Merkmale der Datensammlung ist, wenn man die durchschnittliche Absenkung der Unreinheit in den 200 Entscheidungsbäumen zugrunde legt.
Mean decrease accuracy
Ein weiteres Merkmal-Auswahlverfahren ist die direkte Messung der Auswirkungen jedes Merkmals auf die Genauigkeit des Modells. So besteht die Idee darin, die Werte jedes Merkmals zu vertauschen und dann zu messen, wie sehr die Permutation die Genauigkeit des Modells verringert. Es sollte also erwartet werden, dass die Permutation unwichtiger Merkmale kaum Auswirkungen auf die Präzision des Modells haben, wogegen die Permutation wichtiger Merkmale diese beachtlich reduzieren sollte. Solch ein Auswahlverfahren ist nicht direkt in sklearn implementiert, aber lässt sich einfach implementieren:
from sklearn.cross_validation import ShuffleSplit
from sklearn.metrics import r2_score
from collections import defaultdict
X = df_new.values
Y = target.values
rf = RandomForestRegressor()
scores = defaultdict(list)
for train_idx, test_idx in ShuffleSplit(len(X), 100, .3):
X_train, X_test = X[train_idx], X[test_idx]
Y_train, Y_test = Y[train_idx], Y[test_idx]
r = rf.fit(X_train, Y_train)
acc = r2_score(Y_test, rf.predict(X_test))
for i in range(X.shape[1]):
X_t = X_test.copy()
np.random.shuffle(X_t[:, i])
shuff_acc = r2_score(Y_test, rf.predict(X_t))
scores[x.columns[i]].append((acc-shuff_acc)/acc)
print("Features sortiert nach score:")
print (sorted([(round(np.mean(score), 4), feat) for
feat, score in scores.items()], reverse=True))
Features sortiert nach score:
[(0.5494, 'OverallQual'), (0.1461, 'GrLivArea'), (0.0285, 'TotalBsmtSF'), (0.0194, 'GarageCars'), (0.0176, 'BsmtFinSF1'), (0.0119, '1stFlrSF'), (0.0116, 'YearBuilt'), (0.0112, 'GarageArea'), (0.0098, 'LotArea'), (0.0094, '2ndFlrSF'), (0.0079, 'YearRemodAdd'), (0.0046, 'OverallCond'), (0.0028, 'Fireplaces'), (0.002, 'ExterQual_2'), (0.0017, 'FullBath'), (0.0016, 'KitchenQual_2'), (0.0015, 'CentralAir_0'), (0.0015, 'BsmtUnfSF'), (0.0014, 'Neighborhood_7'), (0.0014, 'BsmtQual_0'), (0.0013, 'WoodDeckSF'), (0.0012, 'OpenPorchSF'), (0.0011, 'MSSubClass'), (0.001, 'BsmtQual_2'), (0.0009, 'KitchenQual_0'), (0.0009, 'BedroomAbvGr'), (0.0008, 'MSZoning_3'), (0.0007, 'ScreenPorch'), (0.0007, 'SaleType_6'), (0.0007, 'Neighborhood_6'), (0.0007, 'Neighborhood_15'), (0.0007, 'LandContour_0'), (0.0007, 'BsmtFullBath'), (0.0006, 'KitchenAbvGr'), (0.0006, 'HalfBath'), (0.0005, 'Neighborhood_17'), (0.0005, 'Condition1_2'), (0.0005, 'BsmtFinType1_2'), (0.0004, 'YrSold'), (0.0004, 'RoofStyle_3'), (0.0004, 'Foundation_2'), (0.0004, 'BsmtExposure_1'), (0.0003, 'MasVnrType_3'), (0.0003, 'Exterior2nd_6'), (0.0003, 'Exterior2nd_13'), (0.0002, 'PavedDrive_0'), (0.0002, 'LotConfig_1'), (0.0002, 'LandSlope_0'), (0.0002, 'HeatingQC_0'), (0.0002, 'Exterior1st_6'), (0.0002, 'Exterior1st_12'), (0.0002, 'BldgType_0'), (0.0001, 'RoofStyle_1'), (0.0001, 'Neighborhood_5'), (0.0001, 'Neighborhood_4'), (0.0001, 'Neighborhood_16'), (0.0001, 'Neighborhood_14'), (0.0001, 'Neighborhood_12'), (0.0001, 'MasVnrType_1'), (0.0001, 'MSZoning_1'), (0.0001, 'MSZoning_0'), (0.0001, 'LotShape_1'), (0.0001, 'LotShape_0'), (0.0001, 'HouseStyle_5'), (0.0001, 'HouseStyle_2'), (0.0001, 'Functional_0'), (0.0001, 'Exterior2nd_8'), (0.0001, 'Exterior2nd_14'), (0.0001, 'Exterior1st_8'), (0.0001, 'Exterior1st_3'), (0.0001, 'ExterQual_0'), (0.0001, 'ExterCond_1'), (0.0001, 'Condition2_4'), (0.0001, 'Condition1_1'), (0.0001, 'BsmtHalfBath'), (0.0001, 'BsmtFinType1_5'), (0.0001, 'BsmtFinSF2'), (0.0001, 'BsmtExposure_0'), (0.0, 'Utilities_0'), (0.0, 'Street_0'), (-0.0, 'SaleType_7'), (0.0, 'SaleType_5'), (0.0, 'SaleType_4'), (0.0, 'SaleType_3'), (0.0, 'SaleType_2'), (-0.0, 'SaleType_1'), (-0.0, 'SaleType_0'), (0.0, 'SaleCondition_4'), (0.0, 'SaleCondition_3'), (-0.0, 'SaleCondition_2'), (-0.0, 'SaleCondition_1'), (0.0, 'SaleCondition_0'), (0.0, 'RoofStyle_4'), (-0.0, 'RoofStyle_2'), (0.0, 'RoofStyle_0'), (0.0, 'RoofMatl_6'), (-0.0, 'RoofMatl_5'), (0.0, 'RoofMatl_4'), (0.0, 'RoofMatl_3'), (0.0, 'RoofMatl_2'), (0.0, 'RoofMatl_0'), (0.0, 'PavedDrive_1'), (0.0, 'Neighborhood_9'), (0.0, 'Neighborhood_8'), (0.0, 'Neighborhood_3'), (0.0, 'Neighborhood_23'), (0.0, 'Neighborhood_22'), (0.0, 'Neighborhood_21'), (0.0, 'Neighborhood_20'), (-0.0, 'Neighborhood_2'), (0.0, 'Neighborhood_19'), (0.0, 'Neighborhood_18'), (0.0, 'Neighborhood_13'), (-0.0, 'Neighborhood_11'), (0.0, 'Neighborhood_10'), (0.0, 'Neighborhood_1'), (-0.0, 'Neighborhood_0'), (0.0, 'MiscVal'), (0.0, 'MasVnrType_2'), (-0.0, 'MasVnrType_0'), (0.0, 'MasVnrArea'), (0.0, 'MSZoning_2'), (-0.0, 'LowQualFinSF'), (0.0, 'LotShape_2'), (0.0, 'LotConfig_3'), (0.0, 'LotConfig_2'), (0.0, 'LandSlope_1'), (0.0, 'LandContour_2'), (-0.0, 'LandContour_1'), (0.0, 'KitchenQual_1'), (-0.0, 'HouseStyle_6'), (-0.0, 'HouseStyle_4'), (-0.0, 'HouseStyle_3'), (0.0, 'HouseStyle_1'), (-0.0, 'HouseStyle_0'), (0.0, 'Heating_4'), (-0.0, 'Heating_3'), (-0.0, 'Heating_2'), (-0.0, 'Heating_1'), (0.0, 'Heating_0'), (0.0, 'HeatingQC_3'), (0.0, 'HeatingQC_2'), (0.0, 'HeatingQC_1'), (0.0, 'Functional_5'), (0.0, 'Functional_4'), (0.0, 'Functional_3'), (-0.0, 'Functional_2'), (-0.0, 'Functional_1'), (-0.0, 'Foundation_4'), (0.0, 'Foundation_3'), (0.0, 'Foundation_1'), (-0.0, 'Foundation_0'), (0.0, 'Exterior2nd_9'), (-0.0, 'Exterior2nd_7'), (-0.0, 'Exterior2nd_5'), (0.0, 'Exterior2nd_4'), (-0.0, 'Exterior2nd_3'), (0.0, 'Exterior2nd_2'), (-0.0, 'Exterior2nd_12'), (-0.0, 'Exterior2nd_11'), (-0.0, 'Exterior2nd_10'), (0.0, 'Exterior2nd_1'), (0.0, 'Exterior2nd_0'), (-0.0, 'Exterior1st_9'), (0.0, 'Exterior1st_7'), (-0.0, 'Exterior1st_5'), (0.0, 'Exterior1st_4'), (0.0, 'Exterior1st_2'), (0.0, 'Exterior1st_13'), (0.0, 'Exterior1st_11'), (0.0, 'Exterior1st_10'), (0.0, 'Exterior1st_1'), (-0.0, 'Exterior1st_0'), (0.0, 'ExterQual_1'), (0.0, 'ExterCond_3'), (0.0, 'ExterCond_0'), (0.0, 'Electrical_4'), (0.0, 'Electrical_3'), (0.0, 'Electrical_2'), (-0.0, 'Electrical_1'), (-0.0, 'Electrical_0'), (0.0, 'Condition2_6'), (0.0, 'Condition2_5'), (0.0, 'Condition2_3'), (-0.0, 'Condition2_2'), (-0.0, 'Condition2_1'), (0.0, 'Condition2_0'), (0.0, 'Condition1_7'), (-0.0, 'Condition1_6'), (0.0, 'Condition1_5'), (0.0, 'Condition1_4'), (-0.0, 'Condition1_3'), (0.0, 'Condition1_0'), (0.0, 'BsmtQual_3'), (0.0, 'BsmtQual_1'), (-0.0, 'BsmtFinType2_5'), (0.0, 'BsmtFinType2_4'), (0.0, 'BsmtFinType2_3'), (-0.0, 'BsmtFinType2_2'), (-0.0, 'BsmtFinType2_1'), (-0.0, 'BsmtFinType2_0'), (0.0, 'BsmtFinType1_4'), (-0.0, 'BsmtFinType1_3'), (0.0, 'BsmtFinType1_1'), (0.0, 'BsmtFinType1_0'), (0.0, 'BsmtExposure_3'), (0.0, 'BsmtExposure_2'), (0.0, 'BsmtCond_3'), (0.0, 'BsmtCond_2'), (0.0, 'BsmtCond_1'), (0.0, 'BsmtCond_0'), (0.0, 'BldgType_3'), (0.0, 'BldgType_2'), (0.0, 'BldgType_1'), (0.0, '3SsnPorch'), (-0.0001, 'ExterCond_2'), (-0.0001, 'EnclosedPorch'), (-0.0002, 'RoofMatl_1'), (-0.0002, 'PoolArea'), (-0.0002, 'Id'), (-0.0004, 'LotConfig_0'), (-0.0011, 'TotRmsAbvGrd'), (-0.0016, 'MoSold')]
OverallQual und GrLivArea sind wie aus der obigen Ausgabe ersichtlich zwei Merkmale, die sich stark auf die Modellleistung auswirken. Das Permutieren verringert die Modellleistung um ~54% bzw. ~14%. Zu beachten gibt es, dass die Messungen erst getätigt wurden, nachdem das Modell für alle Merkmale trainiert wurde und von diesen abhängt. Es bedeutet also nicht, dass die Modellleistung um den angegebenen Betrag sinkt, sobald das Modell ohne einer der Merkmale (OverallQual oder GrLivArea) trainiert wird, da stattdessen andere korrelierte Merkmale verwendet werden können.
Random-Forest Modelle bieten eine einfache Möglichkeit für das Feature-Ranking. In der Regel ist wenig Feature-Engineering notwendig. Zu beachten gibt es, dass bei korrelierten Merkmale ein starkes Merkmal eventuell zu schwach bewertet wird. Solange hier rauf geachtet wird, spricht nichts dagegen diese Modelle auf deine Daten zu testen.

Tareq Haschemi
A man who works with data